今日は、競馬のデータを分析する際に必ずやってほしいことをお伝えします。
実際には多くの「データ分析」でこれが行われていないために、本来は有効ではないデータを使って回収率を低下させてしまっています。
そのような事態を避けるためにもぜひ今回の記事の内容は実践するようにして下さい。
これをするだけでも、書籍や雑誌等のデータに騙されることは大幅に減るはずです。
目次
まずは回収率85%以上(あるいは75%未満)のデータを探す
これまでこのブログでは様々な角度からデータを分析し、その結果を紹介してきました。
それらのデータは1つ1つでは回収率が85%程度しかありませんが、複数データを組み合わせることで回収率は比較的簡単に100%を超えてしまうこともお伝えしました。
これらの記事を読んでさっそくご自身でデータ分析をされている方が大勢いらっしゃいます。
回収率85%のデータを探せばよいのですから難易度は高くないと思いますし、自分で有効なデータを見つけた時の喜びは何とも言えないものがあるので病みつきになってもおかしくはありません。
また同様に、回収率が75%未満のデータを組み合わせることで期待回収率が低いデータをあぶりだすことができることもおわかりいただけたかと思います。
これによって人気馬の評価を客観的に下げることが可能になります。
これらについての詳細はこちらの記事を読んでみて下さい。
今後は回収率85%以上のデータ、あるいは75%未満のデータを見つけていくことでどんどん予想精度が上がると思いますので、ぜひそうやってオリジナルの予想を確立してほしいと思います。
データを分析する上で必ずやってほしいこと
ただ、回収率85%以上(75%未満)のデータを探す際には必ずやってほしいことがあります。
それは「本当にその回収率は信頼できる数字なのか」を確認することです。
どういうことなのか具体例を見てみましょう。
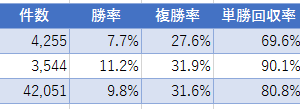
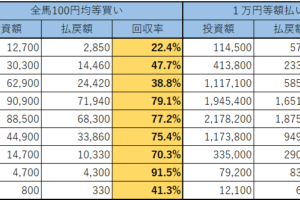
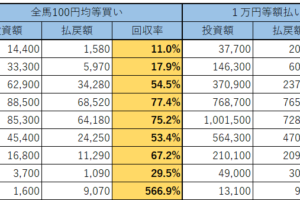
下の成績は2014年1月~2018年12月の5年間のある騎手の成績です(いつもの通り、単勝2~8番人気に絞っています)。

ご覧のように単勝回収率は85%を超えています。
データ数も1000を超えており、一見「この騎手は買い」というようなルールを追加したいと思ってしまうかもしれません。
(この騎手が誰なのかは記事の最後でご紹介します。)
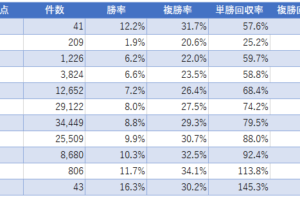
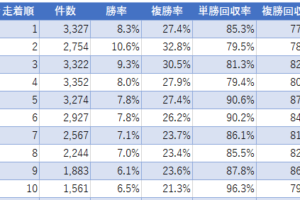
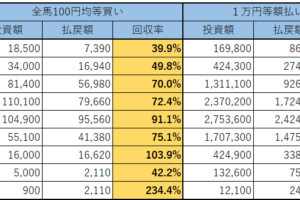
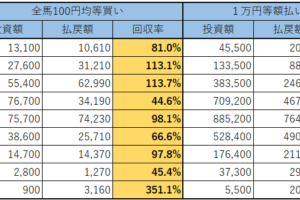
では、次にこれを年別に分けて見てみたいと思います。
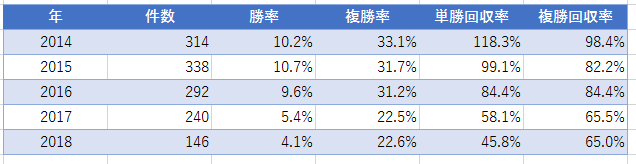
この結果を見ても果たしてこのデータは有効だと言えるでしょうか。
2014年から2018年にかけて単勝回収率は下降一直線です。
最初の2年ではめざましい回収率を叩き出していたものの、最後の2年は60%割れです。
さすがにこれでは「この騎手は買い」というルールを採用する気にはなれないのではないでしょうか。
このように全体で85%を超えているかどうかの確認とは別に、データを細分化したチェックも行うようにしてください。
その際、よく利用されるのがここで行ったような年で分けるような方法です。
単にデータを分けて見れるだけでなく、年ごとの傾向をつかめる可能性もあり、なかなか理にかなった分け方だと思います。
そうやって分けたデータを見た上で「これならルールとして追加しても問題なさそうだ」と判断できた時のみ追加するようにしてください。
安易なルールの追加はこれまでの努力を台無しにする
上のような手順で検証を行うのは、最初のうちはかなり面倒くさいと感じるかもしれません。
しかし、有効でない条件をルールとして採用してしまうと、これまで積み上げてきたルールの精度を大きく落としてしまう可能性があります。
有効な加点・減点ルールを1つずつ見つけて採用していくというのは、実はかなり地道な作業です。
仮説を立てて実際にデータを調べるという作業を繰り返し、ようやく有効なものが一件ようやく見つかるような世界です(この過程は楽しくもあるのですがとにかく時間はかかります)。
そうやって苦労の末に得たプラス1点と、上記の例のように深く検証せずに追加してしまう1点。
この2つが同じ価値として扱われて良いはずがありません。
そして苦労して作り上げてきた評価ルールに無価値な情報が紛れ込んでしまうことによって、本来は期待値が高くない馬券を買ってしまうことにもつながります。
だから条件の追加は極めて慎重に行わなければならないのです。
そのためにはあなた自身がルール採用に関する厳格な基準を設けると良いと思います。
例えば、上で挙げたように年別で集計した上で、「5年のうち4年以上で回収率が85%以上あれば採用」とか「どの年も70%以上ないとダメ」など自分の中でしっくりくる基準を決め、あとは例外なくそれを守るということです。
基準にあと一歩で到達するのに…というデータも出てくると思いますが、そこは鉄の意志を持って切り捨てて下さい。
私が年別の評価をしない理由
先ほどの例では年ごとに分けて集計することがなかなか理に適っていると言いましたが、実は私は年ごとの成績ではなく別の分け方でデータを確認しています。
なぜ年ごとに分類しないかというと、主に以下の3点の理由からです。
その年特有の要因の存在
例えば、ある競馬場で改修が入って他の競馬場で代替開催したような年はデータの傾向が全く変わっても不思議ではありません。
あるいはリーディング上位のジョッキーがケガ等で長期間離脱していたらその騎手はもちろんのこと他の騎手成績には多少なりとも影響があるでしょう。
また、特定の年だけ「払い戻し還元率アップ」のようなキャンペーンを行っていれば回収率に影響があるかもしれません。
このようにその年だけ起こりうる要因というのは少なからず存在すると思っています。
直近の年を強く意識してしまうという主観の排除
2つ目の理由が、年ごとにデータを分けると直近の傾向を重んじてしまうことがあるためです。
例えば先ほどの騎手の例で言えば、直近の2年の回収率が低いのでルールとして採用する可能性は低そうですが、もしデータの並びが逆で古い年から最近にかけて回収率が上昇していた場合は少し見え方が違うのではないでしょうか?
もちろんそれでも最初の2年の回収率が低すぎるのでこのケースはルールとしては採用はしないかもしれませんが、実際にはもっと判断に迷う「5年のうち4年は有効だけど1年だけ有効ではない」というようなデータなんてザラにあります。
そしてその有効でない1年が、最初の1年である場合と直近の1年である場合とでは、ルールとして採用したくなる気持ちに違いが出てきても不思議ではないと思いませんか?
私も客観的にデータを判断しているつもりでも、直近1年で有効でないとわかってしまうとルールとして採用するのをためらってしまいます。
しかし、本当はこのような「確率的に起こりうる範囲内でたまたま直近1年だけ有効でなかった」というようなデータを自分の主観によって排除したくはないのです。

分類の数が5個では物足りない
過去5年のデータ分析をしている以上、年ごとで区切ると当然5個にしか分けられないのですが、私はデータの有効性を判断するのには5個の集計データでは不十分だと考えています。
というのも私はデータの有効性を検証するのに最終的にちょっとした統計の手法を利用しているのですが、10個程度はデータがないとその手法がきちんと機能しないのです。
これについては次の記事でもう少し詳しく述べたいと思います。
以上3点が私が年で分類をしない主な理由なのですが、実際には「他の多くの人と同じような基準で分析をしたくない」という私自身のちょっとひねくれた性格による部分もあります。
年ごとにデータを分割する方法でも、何もやらないよりは絶対にやった方が良いので、あまり気にせずに実践してください。
実際に私がどんな検証をしているか知りたいという場合だけ、以下のメルマガ読者限定記事をご覧ください。
さて、今回の記事で例に挙げた騎手が誰なのか、答えの発表です。
正解は「柴田善臣騎手」でした。
もしこれがわかった方がいたらマニア過ぎますね…。